wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading · GitHub
Por um escritor misterioso
Descrição
This repository contains the three WikiReading datasets as used and described in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia, Hewlett, et al, ACL 2016 (the English WikiReading dataset) and Byte-level Machine Reading across Morphologically Varied Languages, Kenter et al, AAAI-18 (the Turkish and Russian datasets). - wiki-reading/data/answer.vocab at master · google-research-datasets/wiki-reading

Reflection on current project state, and a proposal for a metaschema · Issue #23 · jupyterlab/jupyterlab-metadata-service · GitHub
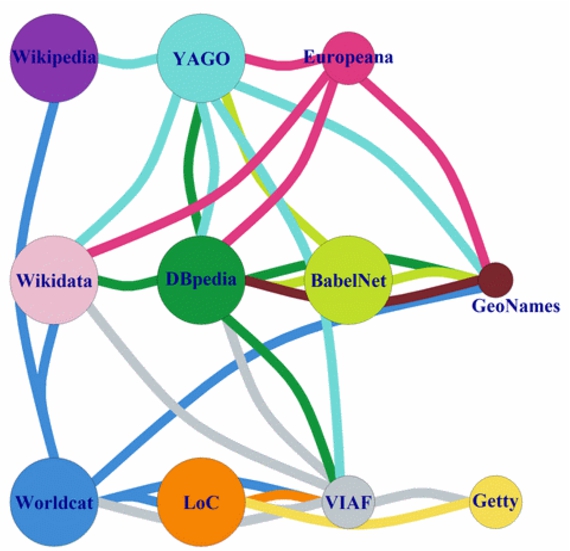
Instance level analysis on linked open data connectivity for cultural heritage entity linking and data integration - IOS Press
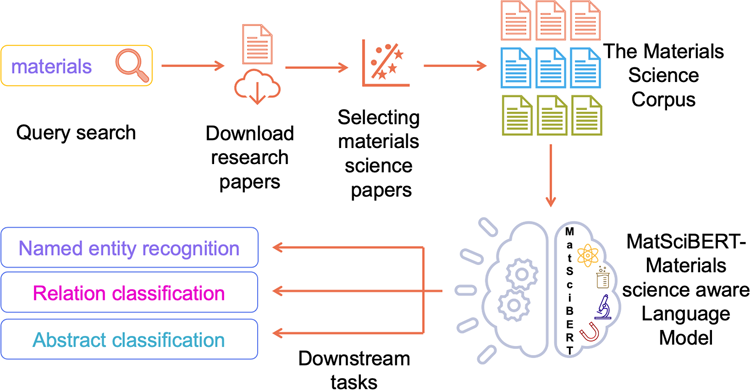
MatSciBERT: A materials domain language model for text mining and information extraction
GitHub - awesomedata/awesome-public-datasets: A topic-centric list of HQ open datasets.
Using natural language generation to bootstrap missing Wikipedia articles: A human-centric perspective - IOS Press
🔓 Unlocking the power of the ChatGPT revolution: 100 💥 innovative use-cases to try before you 💔 are fired 🔥, by Florin Badita
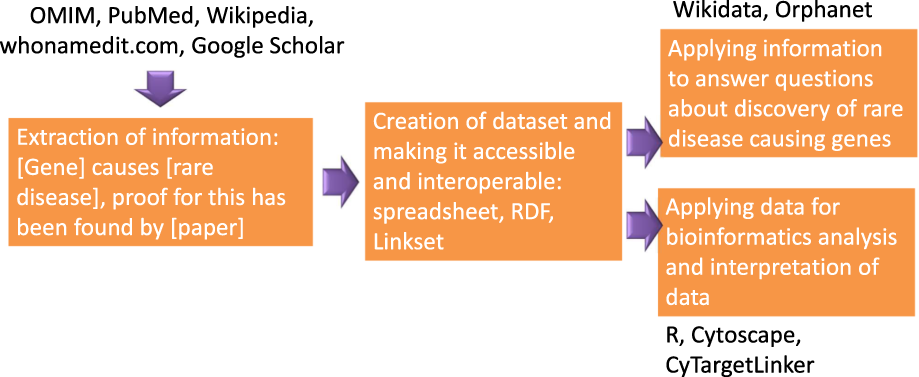
A resource to explore the discovery of rare diseases and their causative genes

A survey of consumer health question answering systems - Welivita - AI Magazine - Wiley Online Library
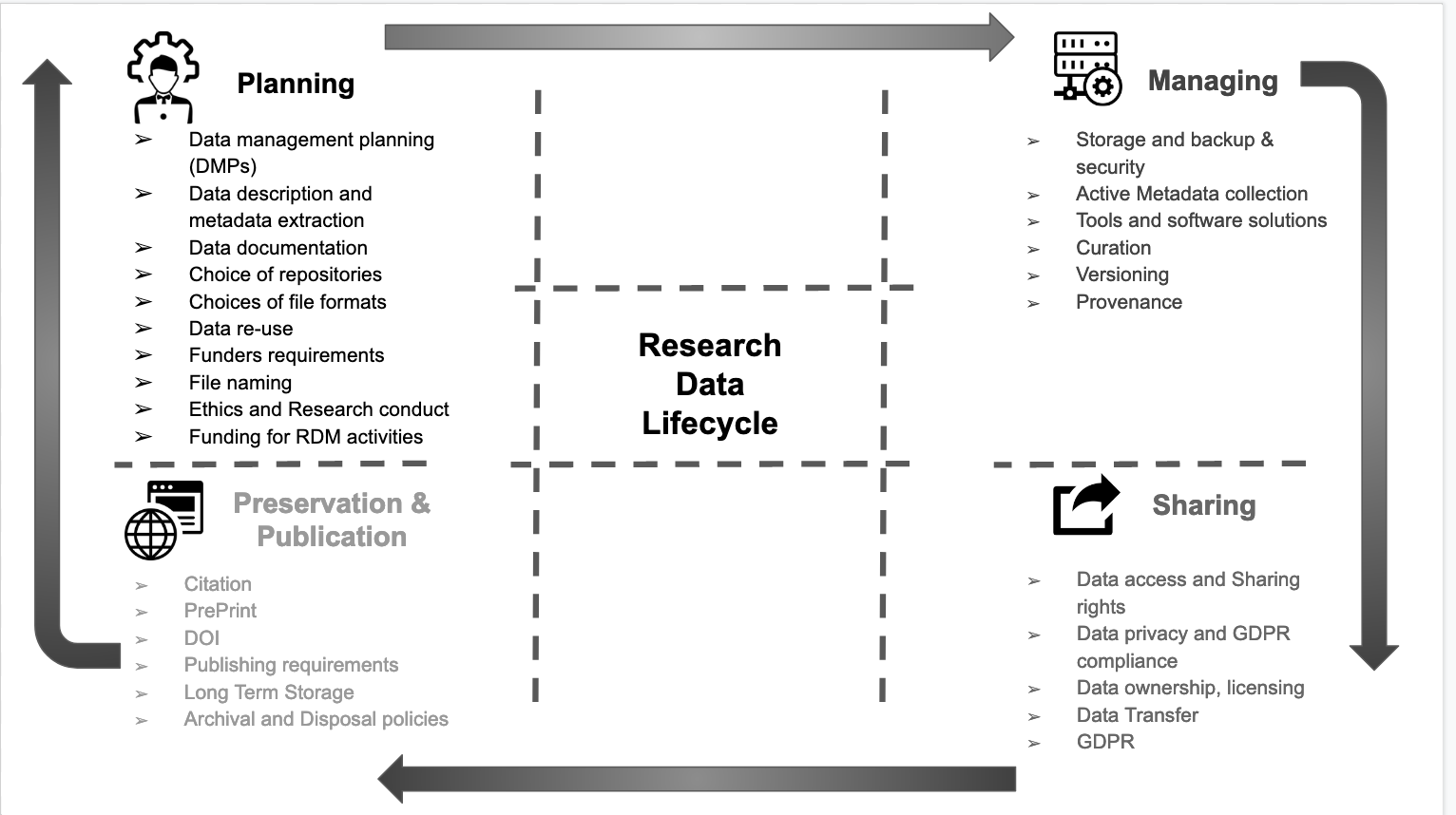
Library Carpentry: FAIR Data and Software
GitHub - google-research-datasets/wiki-translated-clusters-nli: A collection of 5K introductions to popular English Wikipedia articles, with their parallel versions in 10 other languages, and machine translations to English. Also includes a

PDF) Dataset Reuse: Toward Translating Principles to Practice

AI-based Question Answering Assistance for Analyzing Natural-language Requirements – arXiv Vanity
de
por adulto (o preço varia de acordo com o tamanho do grupo)






