XQuAD Dataset Papers With Code
Por um escritor misterioso
Descrição
XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
P] Browse State-of-the-Art Papers with Code : r/MachineLearning

Datasets em português - NLP com o Deep Learning - AI Lab Deep
GitHub - ElizaLo/Question-Answering-based-on-SQuAD: Question
GitHub - google-deepmind/xquad
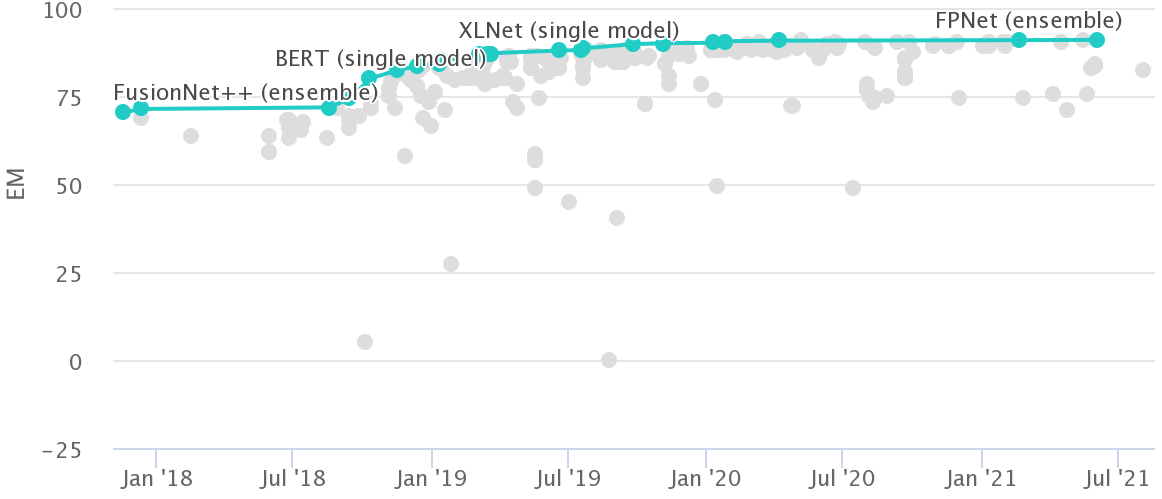
Challenges and Opportunities in NLP Benchmarking
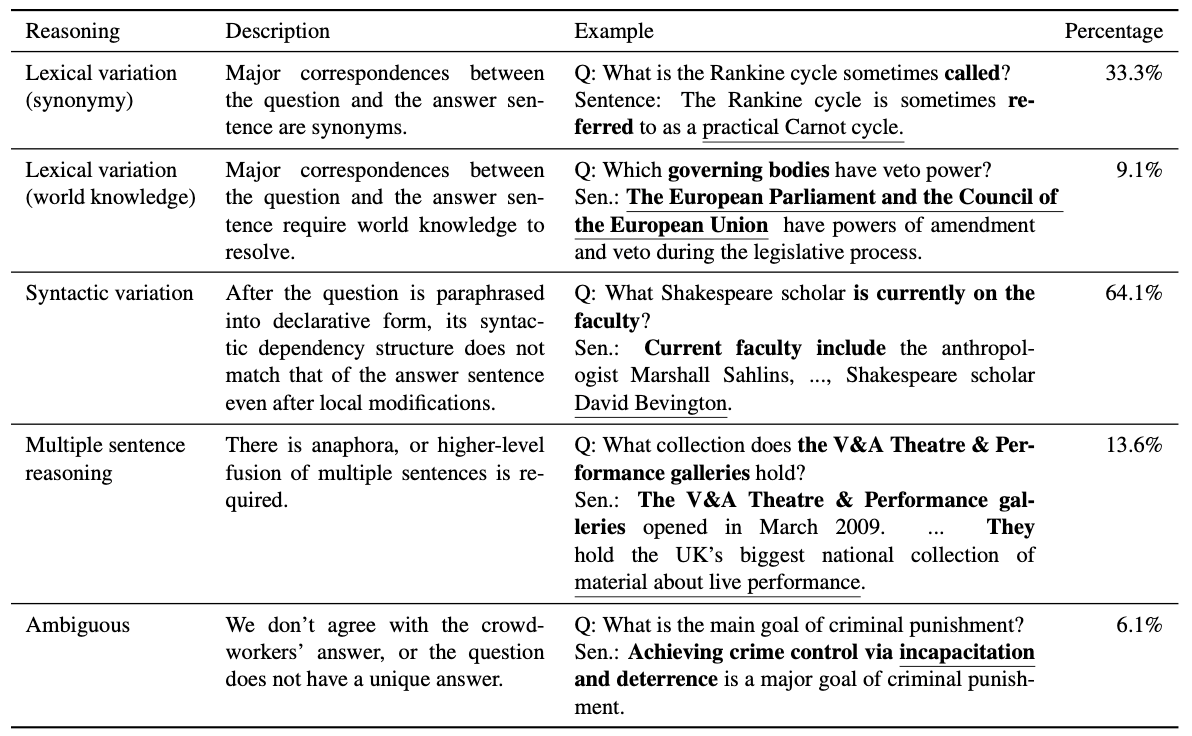
The Quick Guide to SQuAD. All the basic information you need to

How SIGNAL IDUNA operationalizes machine learning projects on AWS

XQuAD (de) Benchmark (Question Generation)

Papers with code or without code? Impact of GitHub repository

Snorkel AI researchers present 18 papers at NeurIPS 2023
de
por adulto (o preço varia de acordo com o tamanho do grupo)